Introducing Zod Codecs
Colin McDonnell @colinhacks
published August 23rd, 2025
Zod 4.1 introduced a new z.codec() API for defining bi-directional transformations in Zod.
The problem with transforms
Zod's .transform() method is great for one-way data conversion:
const stringToNumber = z.string().transform(val => parseFloat(val));
stringToNumber.parse("42"); // 42But what if you need to go both ways? Say, you're storing dates as ISO strings in a database but want to work with Date objects in your app.
const stringToDate = z.string().transform(str => new Date(str));
const dateToString = z.date().transform(date => date.toISOString());
// Two separate schemas, manually kept in sync
stringToDate.parse("2024-01-15T10:30:00.000Z"); // Date
dateToString.parse(new Date()); // "2024-01-15T10:30:00.000Z"This works, but it's brittle. You need to keep track of two schemas and remember that they are intended as inverses. You need to manually verify that the output type of one matches the input type of the other. If you change one, you have to remember to update the other.
Introducing codecs
Codecs are a new Zod API for defining bidirectional transformations between two types. You specify an input schema, output schema, and transformation functions in both directions:
const stringToDate = z.codec(
z.iso.datetime(), // input schema: ISO string
z.date(), // output schema: Date object
{
decode: isoString => new Date(isoString), // string → Date
encode: date => date.toISOString(), // Date → string
}
);You can process data in both directions using the new top-level .decode() and .encode() methods:
stringToDate.decode("2024-01-15T10:30:00.000Z"); // Date
stringToDate.encode(new Date("2024-01-15")); // "2024-01-15T00:00:00.000Z"Note — For bundle size reasons, these new methods have not added to Zod Mini schemas. Instead, this functionality is available via equivalent top-level functions.
// equivalent at runtime z.decode(stringToDate, "2024-01-15T10:30:00.000Z"); z.encode(stringToDate, new Date());
This is particularly important when you are using Zod to map data back and forth between two different domains. One common use case is to convert data to/from a serializable format like JSON into a richer JavaScript representation (with Date, bigint, etc).

Async
The transformation functions can be async.
const asyncCodec = z.codec(z.string(), z.number(), {
decode: async str => Number(str),
encode: async num => num.toString(),
});The usual "safe" and "async" variants exist:
syncCodec.encode("42");
syncCodec.safeEncode("42");
await asyncCodec.encodeAsync("42");
await asyncCodec.safeEncodeAsync("42");Composability
Codecs can be composed inside other schemas, just like any other schema. There are no special rules.
const queryParams = z.object({
before: stringToDate,
after: stringToDate
})
queryParams.encode({
before: new Date(),
after: new Date()
});
// => { before: string, after: string }.parse() vs .decode()
Let's compare the existing .parse() APIs to .decode(). .parse() is equivalent to .decode() at runtime.
// equivalent at runtime
stringToDate.parse("2024-01-15T10:30:00.000Z");
stringToDate.decode("2024-01-15T10:30:00.000Z");Though they're identical at runtime, their type signatures differ in an important way. While .parse() accepts unknown, decode expects a strongly-typed inputs.
stringToDate.parse(12345);
// No TypeScript error but fails at runtime
stringToDate.decode(12345);
// ❌ TypeScript error: Argument of type 'number' is not assignable to parameter of type 'string'Here's a diagram demonstrating the differences:
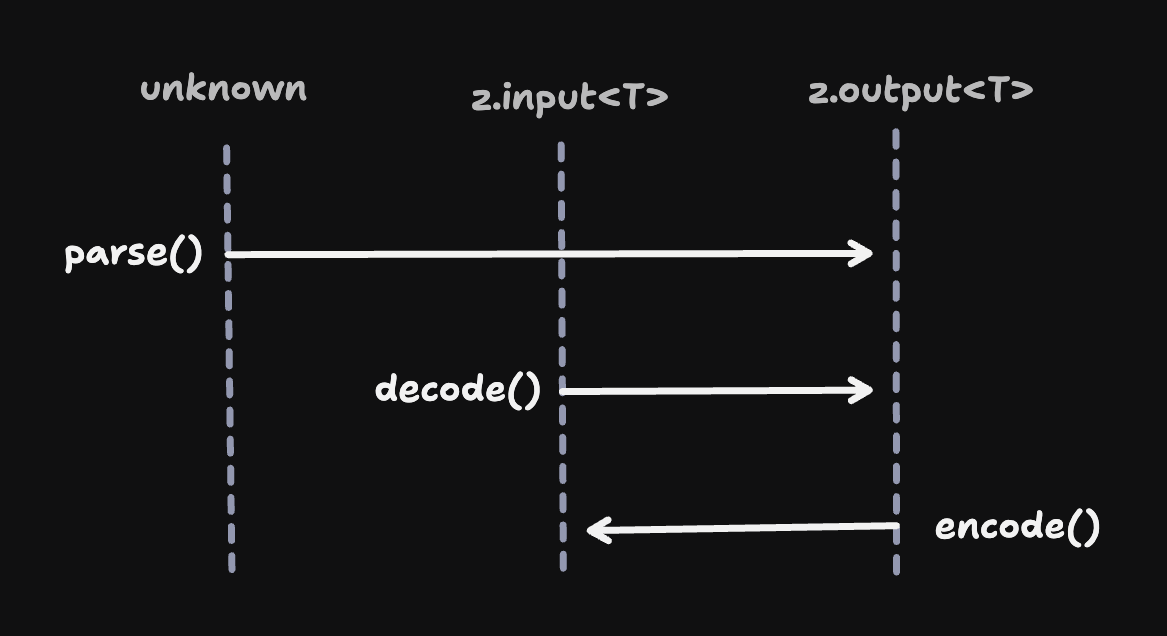
This is a highly requested feature unto itself.
How encoding works
Most Zod schemas in the universe don't perform any kind of transformation. Their inferred input and output types are identical. For these schemas, there is no difference between parsing/decoding and encoding.
const mySchema = z.object({
name: z.string()
});
// no difference
mySchema.parse({ name: "colinhacks" });
mySchema.decode({ name: "colinhacks" })
mySchema.encode({ name: "colinhacks" })A small number of APIs cause the input and output types to diverge. In these scenarios, the runtime behavior of .decode()/.encode() also differ.
Codecs
This is an obvious one. During .decode(), the decode function runs. During .encode(), the encode function runs. Simple.
Transforms ⚠️
This is the #1 rule of .encode(): you can't use .transform(). That API is inherently unidirectional. If your schema contains any transforms, attempting an "encode" operation with it will throw a runtime error. You'll need to refactor to use z.codec().
const schema = z.string().transform(val => val.length);
schema.encode(5);
// ❌ ZodEncodeError: Encountered unidirectional transform during encodePipes
Note — Codecs are actually implemented as a subclass of
ZodPipeaugmented with "interstitial" transform logic.
Pipes reverse their order during encoding, from A → B to B → A. That said, pipes are typically used in conjunction with transforms, so "vanilla" pipes are rarely useful in the context of encoding. Prefer z.codec() everywhere.
Refinements
All checks (.refine(), .min(), .max(), etc.) are still executed in both directions.
const schema = stringToDate.refine((date) => date.getFullYear() > 2000, "Must be this millenium");
schema.encode(new Date("2000-01-01"));
// => Date
schema.encode(new Date("1999-01-01"));
// => ❌ ZodError: [
// {
// "code": "custom",
// "path": [],
// "message": "Must be this millenium"
// }
// ]To avoid unexpected errors in your custom .refine() logic, Zod performs two "passes" during .encode(). The first pass ensures the input type conforms to the expected type (no invalid_type errors). If that passes, Zod performs the second pass which executes the refinement logic.
This approach means all parsing & refinement logic runs in exactly the reverse order during encoding. Even "mutating refinements" like z.string().trim() or z.string().toLowerCase() work as expected.
const schema = z.string().trim();
schema.decode(" hello ");
// => "hello"
schema.encode(" hello ");
// => "hello"Default/prefault
Default and prefault values are only applied in the forward direction.
const withDefault = z.string().default("hello");
withDefault.decode(undefined); // "hello"
withDefault.encode(undefined); // ❌ ZodErrorThis is by design. When you add a default, the input becomes string | undefined but the output stays string. As such, undefined isn't considered a valid input to .encode().
Catch
Similarly, .catch() values are only applied in the forward direction.
Stringbool
Note — Stringbool pre-dates the introduction of codecs in Zod. It has since been internally re-implemented as a codec.
The z.stringbool() API converts string values ("true", "false", "yes", "no", etc.) into boolean. By default, it will convert true to "true" and false to "false" during .encode()..
const stringbool = z.stringbool();
stringbool.decode("true"); // => true
stringbool.decode("false"); // => false
stringbool.encode(true); // => "true"
stringbool.encode(false); // => "false"If you specify a custom set of truthy and falsy values, the first element in the array will be used instead.
const stringbool = z.stringbool({ truthy: ["yes", "y"], falsy: ["no", "n"] });
stringbool.encode(true); // => "yes"
stringbool.encode(false); // => "no"Official codecs
Zod doesn't provide any predefined codecs out of the box. Instead, the docs provide some "canonical" codec implementations you can copy/paste into your projects as needed. These have all been tested internally.
stringToNumberstringToIntstringToBigIntnumberToBigIntisoDatetimeToDateepochSecondsToDateepochMillisToDatejsonCodecutf8ToBytesbytesToUtf8base64ToBytesbase64urlToByteshexToBytesstringToURLstringToHttpURLuriComponentstringToBoolean
Some selected examples are below.
stringToBigInt
const stringToBigInt = z.codec(z.string(), z.bigint(), {
decode: str => BigInt(str),
encode: bigint => bigint.toString(),
});
stringToBigInt.decode("12345"); // 12345n
stringToBigInt.encode(12345n); // "12345"jsonCodec
const jsonCodec = z.codec(z.string(), z.json(), {
decode: (jsonString, ctx) => {
try {
return JSON.parse(jsonString);
} catch (err: any) {
ctx.issues.push({
code: "invalid_format",
format: "json_string",
input: jsonString,
message: err.message,
});
return z.NEVER;
}
},
encode: value => JSON.stringify(value),
});You can pipe jsonCodec into other schemas for additional validation:
const UserFromJson = jsonCodec.pipe(z.object({
name: z.string(),
age: z.number()
}));
UserFromJson.decode('{"name":"Alice","age":30}'); // { name: "Alice", age: 30 }
UserFromJson.encode({ name: "Bob", age: 25 }); // '{"name":"Bob","age":25}'base64ToBytes
const base64ToBytes = z.codec(z.base64(), z.instanceof(Uint8Array), {
decode: base64String => z.core.util.base64ToUint8Array(base64String),
encode: bytes => z.core.util.uint8ArrayToBase64(bytes),
});
base64ToBytes.decode("SGVsbG8="); // Uint8Array([72, 101, 108, 108, 111])
base64ToBytes.encode(bytes); // "SGVsbG8="For further reading, see the Zod 4.1 release notes and the Codecs documentation page.